
Elon Musk announced the launch of Grok, a new large language generative AI model created after “Hitchhiker’s Guide to the Galaxy” and intended to answer almost anything and, far more difficult, even suggest what questions to ask!
Grok will be integrated into X, formerly known as Twitter, and is designed to respond to questions with a sense of humour. In fact, the company advises against using Grok if you dislike humour.
Grok is capable of answering “spicy questions” that most other AI models reject, thanks to real-time knowledge of the world provided by the X platform. The company claims that this four-month-old generative AI model with two months of training will be improved in the coming days.
The Goal of Grok AI
Grok, according to xAI, was created to help humanity understand and learn. It is powered by Grok-1 LLM, which was created over a four-month period. The prototype Grok-0 was trained with 33 billion parameters, and it is said to be as powerful as Meta’s LLaMA 2, which can handle 70 billion parameters.
Understanding Abilities
Benchmarks show that the Grok-1 achieves 63.2% on the HumanEval coding task and 73% on the MMLU. While it is still not as capable as GPT-4, xAI claims that it has improved the performance of Grok-1 when compared to Grok-0 in a short period of time.
According to the benchmark results, Grok-1 achieved 62.9 percent on GSM8k (Cobbe et al. 2021), a benchmark designed around middle-class math word problems, which is higher than GPT-3.5 and LLaMa 2 but lower than Palm 2, Claude 2, and GPT-4.
The same is true for other benchmarks such as MMLU (Hendrycks et al. 2021), a multi-choice question benchmark, HumanEval (Chen et al. 2021), a Python code generation test, and MATH (Hendrycks et al. 2021), a middle and high school mathematical test written in LaTeX.
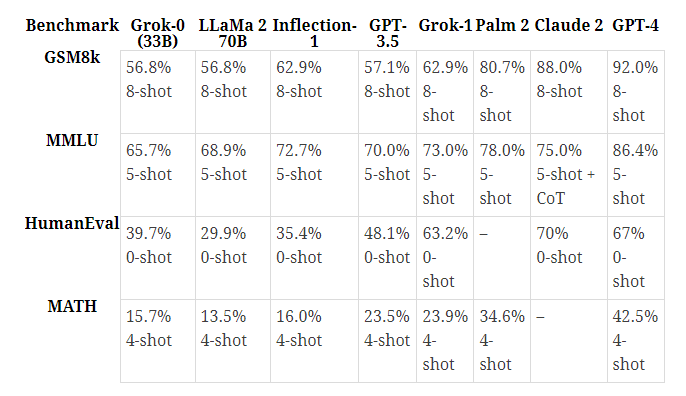
Similarly, xAI hand-graded Grok-1, which passed the 2023 Hungarian national high school finals in mathematics with a C grade (59%), surpassing the performance of Claude 2 (55%), while the GPT-4 received a B grade (68%).
These figures clearly show that Grok-1 is more capable than OpenAI’s GPT-3.5, but not as capable as the most recent model, GPT-4. The company also claims that Grok-1, despite being trained on less data, can outperform models that have been trained on large amounts of data and require more computing power.
Given Below are Some Adaptive Features of Twitter |
Follow and Connect with us on
Facebook | Instagram | Linkedin | Dribbble | Twitter | Tumblr | Pinteres










{kind=link}